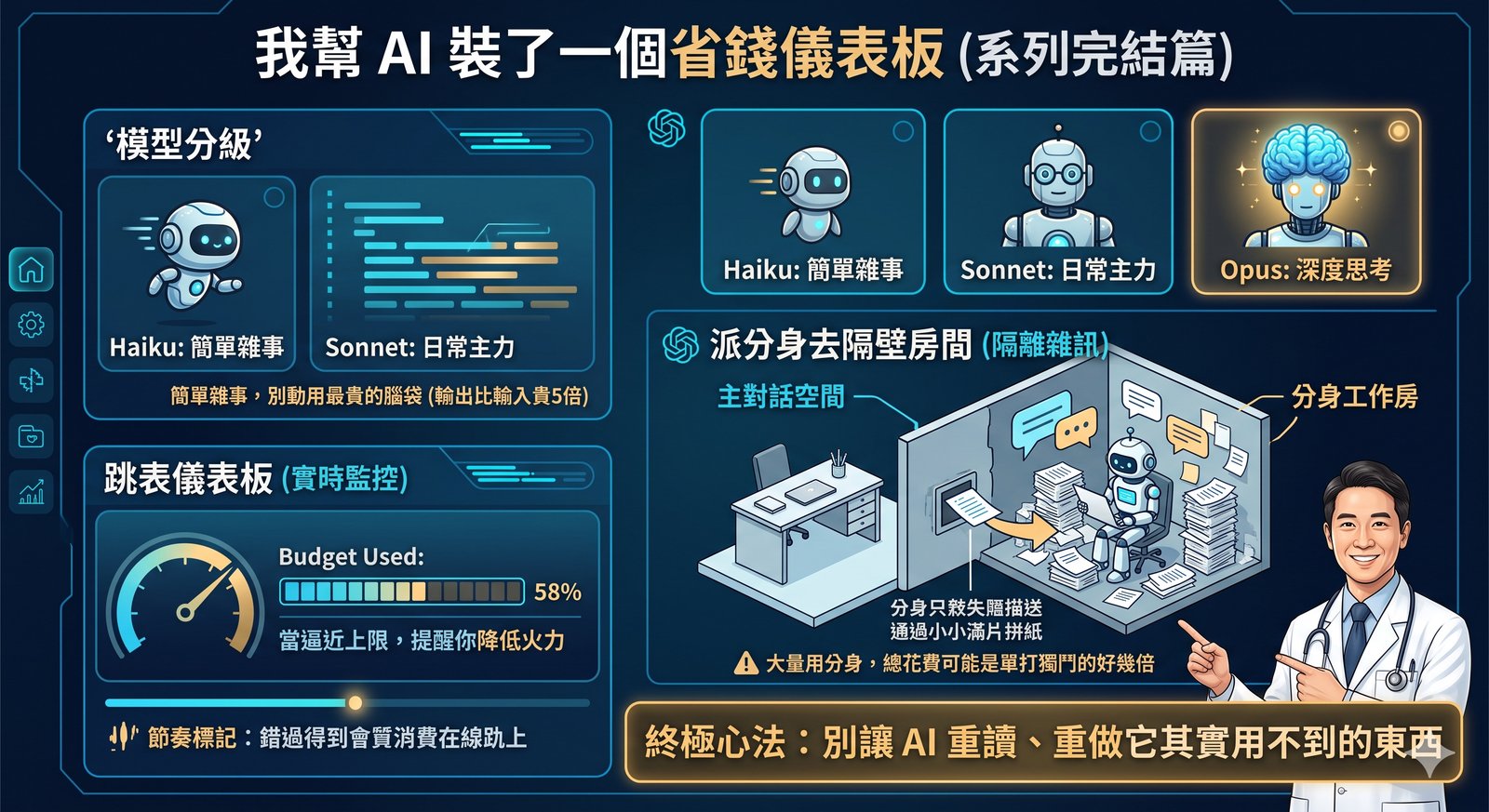
我幫 AI 裝了一個省錢儀表板
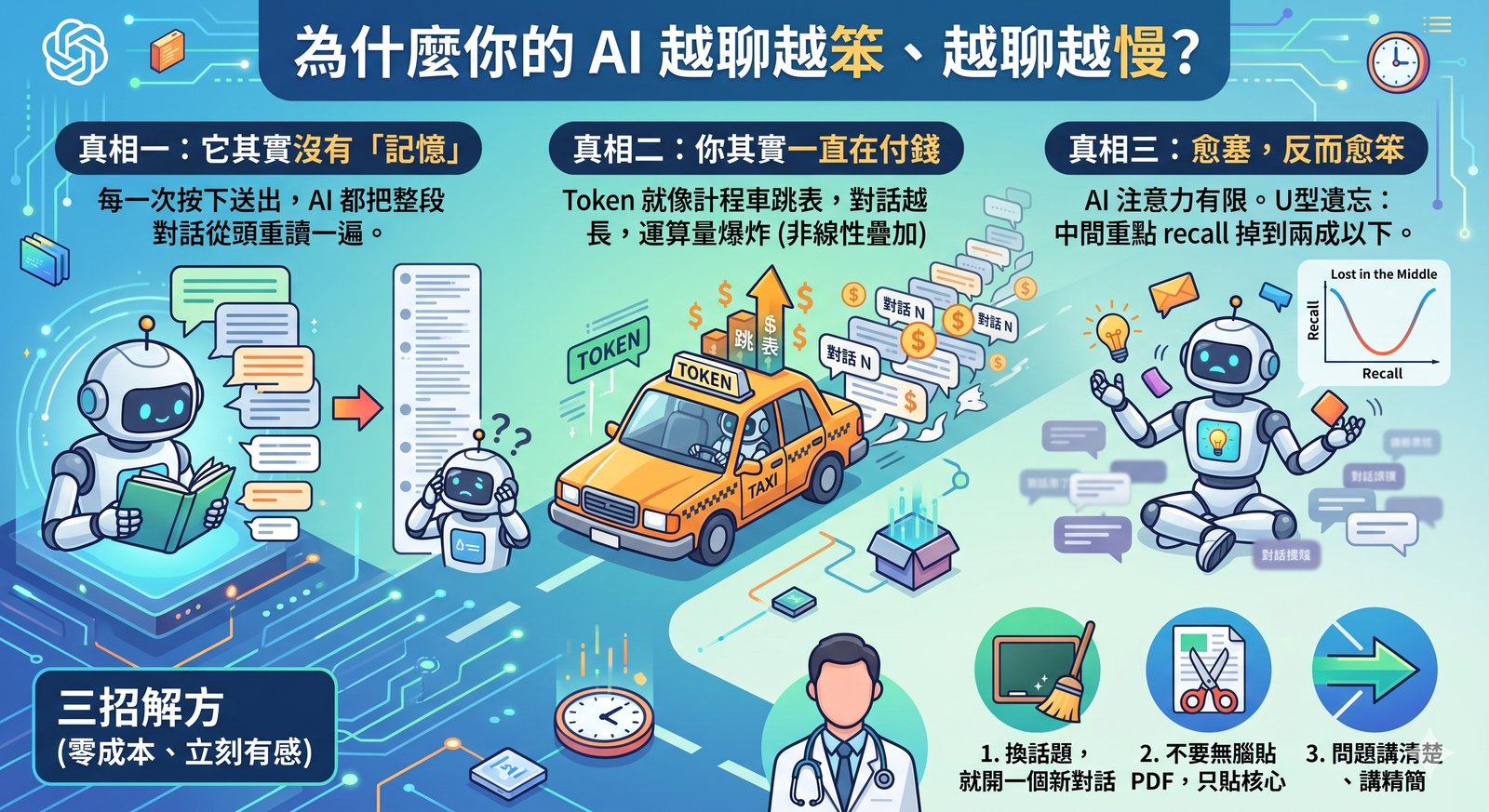
📖 省 Token 系列(共四篇):第一篇 為什麼你的 AI 越聊越笨 · 第二篇 能用算盤就別開超級電腦 · 第三篇 幫 AI 整理一張乾淨的工作桌 · 第四篇(本篇,完結) 來到系列最後一篇。前三篇我們從「為什麼 AI 越聊越笨」,一路講到「什麼時候別用 AI」「怎麼幫它整理桌面」。這一篇談的是錢真正花下去的那一刻:怎麼把每一塊錢花在刀口上。 第一件事:不是每件事都需要最聰明的腦袋(但省下來,就是為了負擔得起好的) AI 模型有分等級。以 Claude 為例,由便宜到貴大致是 Haiku、Sonnet、Opus 三級,價差很大。 如果你是按使用量付費的人,最直接的省法就是「派對的等級做對的事」:改格式、重新命名、簡單分類這種雜事,交給最便宜的 Haiku 就好;日常的寫作、查資料用中間的 Sonnet;只有真正需要深度推理的硬任務,才動用最強的 Opus。 這裡還有一個很多人都搞錯的觀念,特別講一下:「要看圖」不等於「要用最貴的模型」。 當你只是要 AI「看一張圖、認出裡面有什麼、把上面的字讀出來」這種辨識任務,最便宜的 Haiku 通常就完全夠用,便宜到一個誇張。只有要它「看懂一張複雜的醫學示意圖、解讀圖表背後的邏輯」這種需要推理的視覺任務,才值得升級。選模型的真正標準,是「這個任務需要多少思考」,不是「要不要看圖」。 不過老實說,我自己現在反而大多直接用最強的 Opus,XD。 為什麼?因為我發現,在目前的訂閱方案下,把前面三篇那些省 token 的功夫都做好之後,我的額度其實用不太完,而最強的模型品質又明顯比較好。所以對我來說,與其斤斤計較每件事該用哪一級,不如把省下來的額度,拿去讓最好的模型做每一件事。 我覺得這反而是整個系列最想講的一件事:省 token 從來不是為了小氣。 我把浪費擋掉、把該交給程式的交給程式、把桌面整理乾淨,省下來的這些,剛好讓我負擔得起「把最好的腦袋,用在每一個我在乎的問題上」。省,是為了能大方地花在刀口上。 最後補兩個進階的小心法: 讓 AI 少廢話,可以一勞永逸。 AI 的「輸出」比「輸入」貴上好幾倍(以 Opus 為例差到五倍),所以請它回答精簡就是直接省錢。而且這件事你不用每次重講,直接寫進給它的長期指令裡(就是第三篇那份常駐設定檔,或聊天版的「自訂指令」),叫它預設就講重點、不要長篇大論。一次設定,之後每次都省。 思考深度也能調。 同一個模型可以設定它「想多深」,簡單的事用淺一點、難的事才開深度思考。重點永遠是:把力氣花在真正難的地方。 第二件事:把吵鬧的雜事,丟到隔壁房間做 有些工作會吐出一大堆過程訊息:跑一輪測試、抓一份長文件、處理一堆紀錄。如果讓這些雜訊全部堆在主對話裡,桌面馬上被淹沒(回到第三篇,桌面一髒就又貴又笨)。 我的做法是派一個「分身」去隔壁房間做這件事。分身有自己獨立的工作空間,它的所有過程、雜訊、草稿都留在那個房間裡,只有最後的結論回到我的主對話。 這就像你請助理去查一整天資料,你不需要看他翻過的每一頁,只要他最後給你一頁重點。 但這招有取捨,我必須老實說:派分身本身也要花錢,而且分身會自己燒一輪 token。官方就提醒過,大量用分身的工作流,總花費可能是單打獨鬥的好幾倍。所以原則是:當「保持主桌面乾淨」的價值,大於「多請一個分身」的成本時,才派。 不是什麼都丟分身。 (這篇從頭到尾,你會發現省 token 沒有一招是無腦的,每一招都在權衡。這正是它好玩的地方。) 第三件事:裝一個會對我跳表的儀表板 講了這麼多省法,最後一塊拼圖是:你得看得見自己花了多少。 看不見的支出最危險。所以我裝了一個開源小工具,叫 cc-budget(由 boyand 開發,在 GitHub 上找得到)。 ...