把圖檢索加進我的醫學 LLM Wiki,這次真的有用了
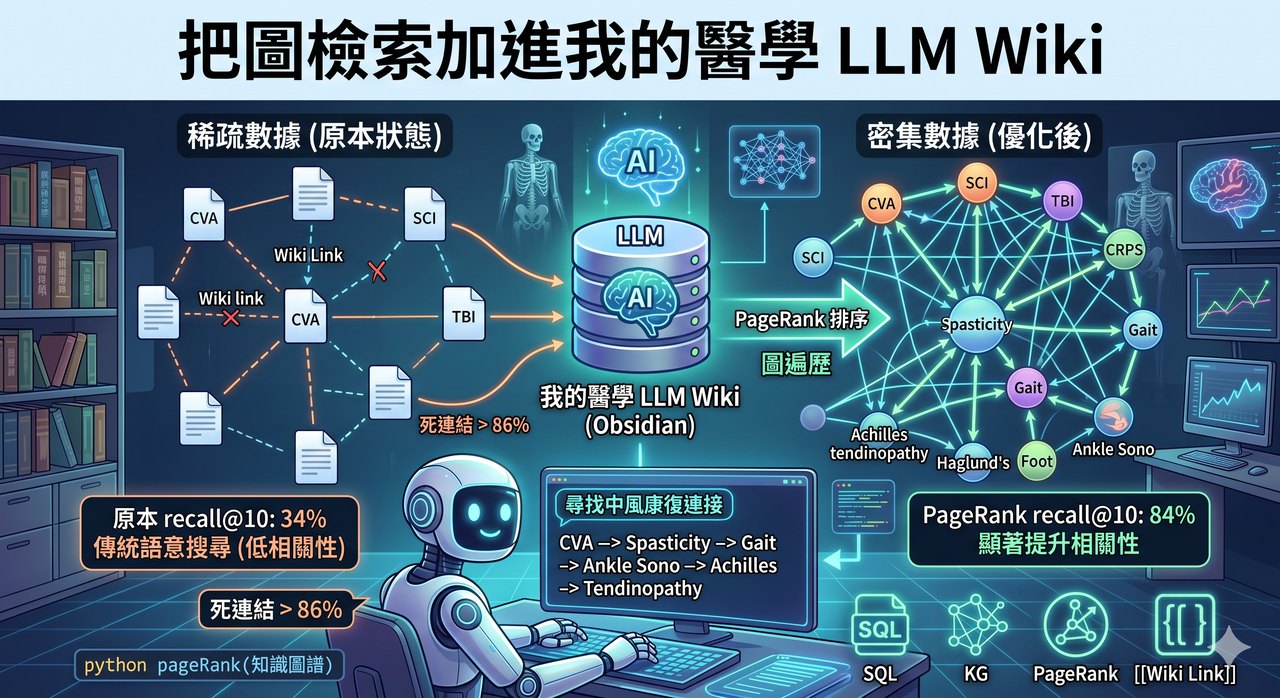
背景:我本來就在用的東西 念專科考試的時候,我給自己弄了一套 RAG(Retrieval Augmented Generation),用「看相似度」的語意搜尋(semantic search)把幾百本復健科教科書跟我自己的筆記變成可以查、可以問的東西。一邊在 Obsidian 裡讀書用,一邊讓 Claude 透過 MCP 也能找到我要的東西。 它目前最弱的地方,就是「跨文獻把知識串起來」。所以前幾天看到有人分享一篇剛發表的論文 SAG(SQL-Retrieval Augmented Generation),說可以在語意搜尋之外加上結構化查詢語言(SQL)跟圖的概念,讓跨文獻搜尋更容易,效果類似 GraphRAG 但更好維護、更好建立,我整個眼睛一亮。 在這時代想當然爾,就是把論文連結丟給 Claude,請他去讀論文、抓原作者的 GitHub、讀懂作法,然後用我自己的資料把整條管線複現出來、實際跑 benchmark XD 論文:Wu et al., SAG: SQL-Retrieval Augmented Generation with Query-Time Dynamic Hyperedges, arXiv:2606.15971。程式碼:github.com/Zleap-AI/SAG-Benchmark 第一步:選模型(RTX-3070 的眼淚) 整條管線裡最關鍵的一步,是用 LLM 把每段文字抽成「事件 + 實體」存進資料庫。原論文用 Qwen,我就比了本地的 Qwen(qwen3.5:4b)跟線上的 Claude Haiku。 結果 Haiku 萃取資訊的能力明顯比較好,實體圖更密、命名更一致(這對後面用 SQL 串很重要),而且看起來很便宜。這跟我先前的經驗相符,可能我的 RTX-3070 真的太弱了,稍微大一點的模型就跑不動(時代的眼淚阿),直接用 Haiku 又快又好! 順帶一提,我沒有 API 訂閱也能用 Haiku:直接派 Claude 的 subagent 去做,跑在既有額度內就好。 教科書上的三個發現(一路打臉) 我用神經復健的教科書當測試語料,設計了一批臨床問題,拿 SAG 跟原本的語意搜尋正面對決。結果分三關,每一關都打我臉一次。 第一關,單一本書:打平。語意搜尋已經夠強,多跳機制沒用武之地。 第二關,跨書、但問題裡把關鍵字都寫白了:還是打平。因為問題裡已經把「中風、脊張力、步態」全寫出來,語意搜尋自己就把相關段落都撈回來了。 第三關,跨書、但只問一端、中間那跳故意不講(例如只問「馬蹄內翻足怎麼處理」,期待它自己連到背後的脊張力機轉跟治療):SAG 終於贏了,而且贏很多。 ...