幫 AI 整理一張乾淨的工作桌
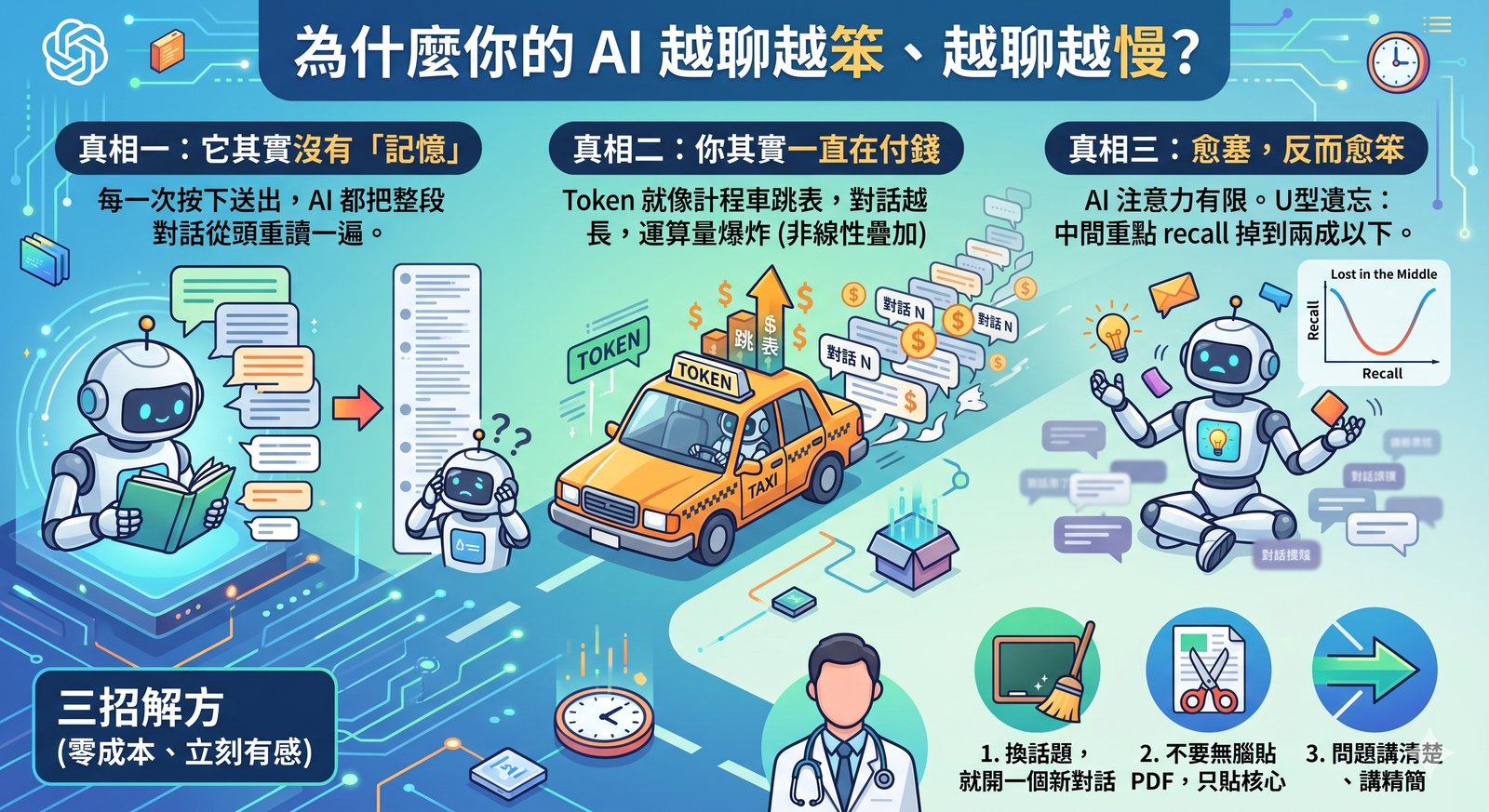
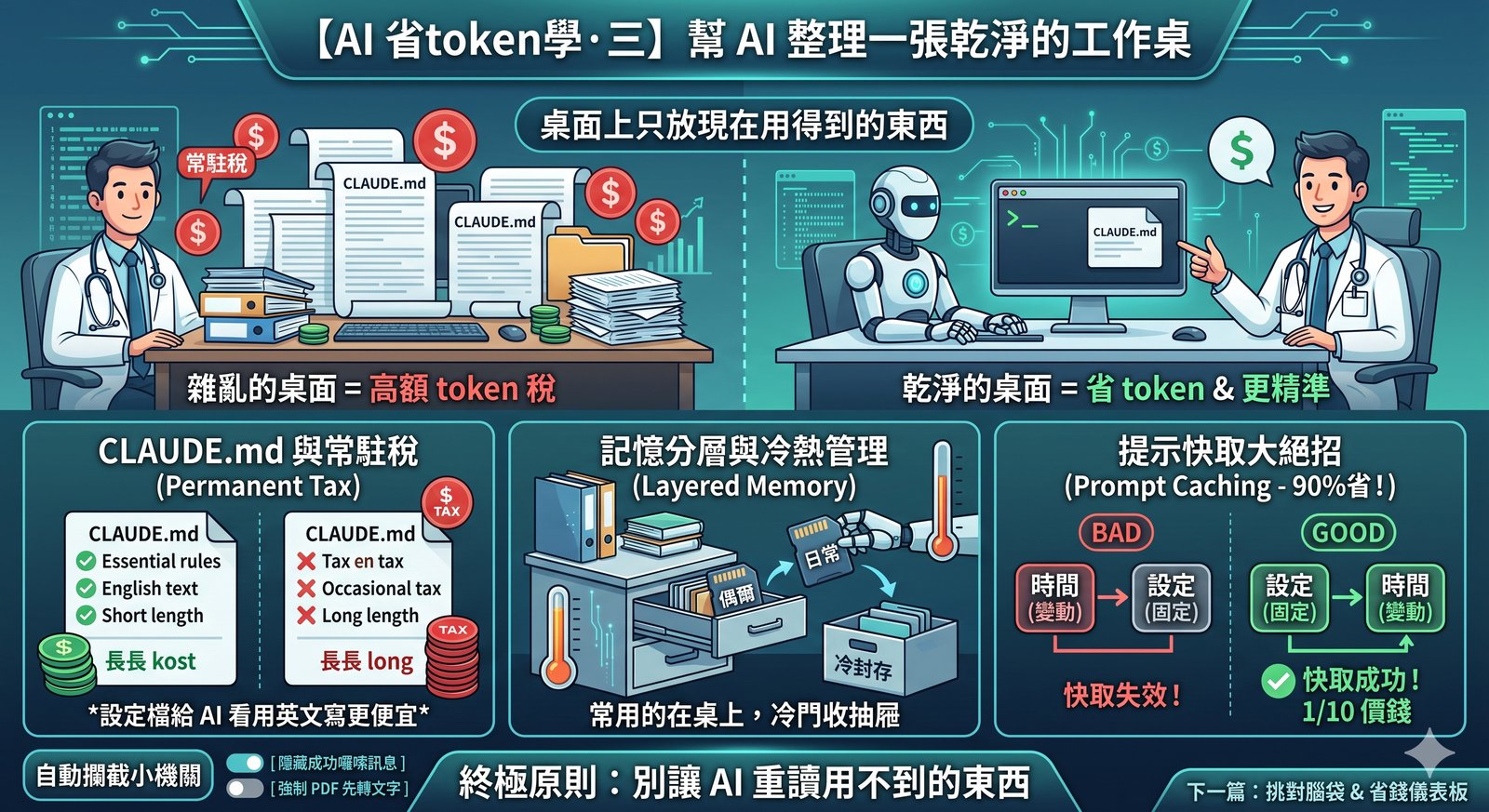
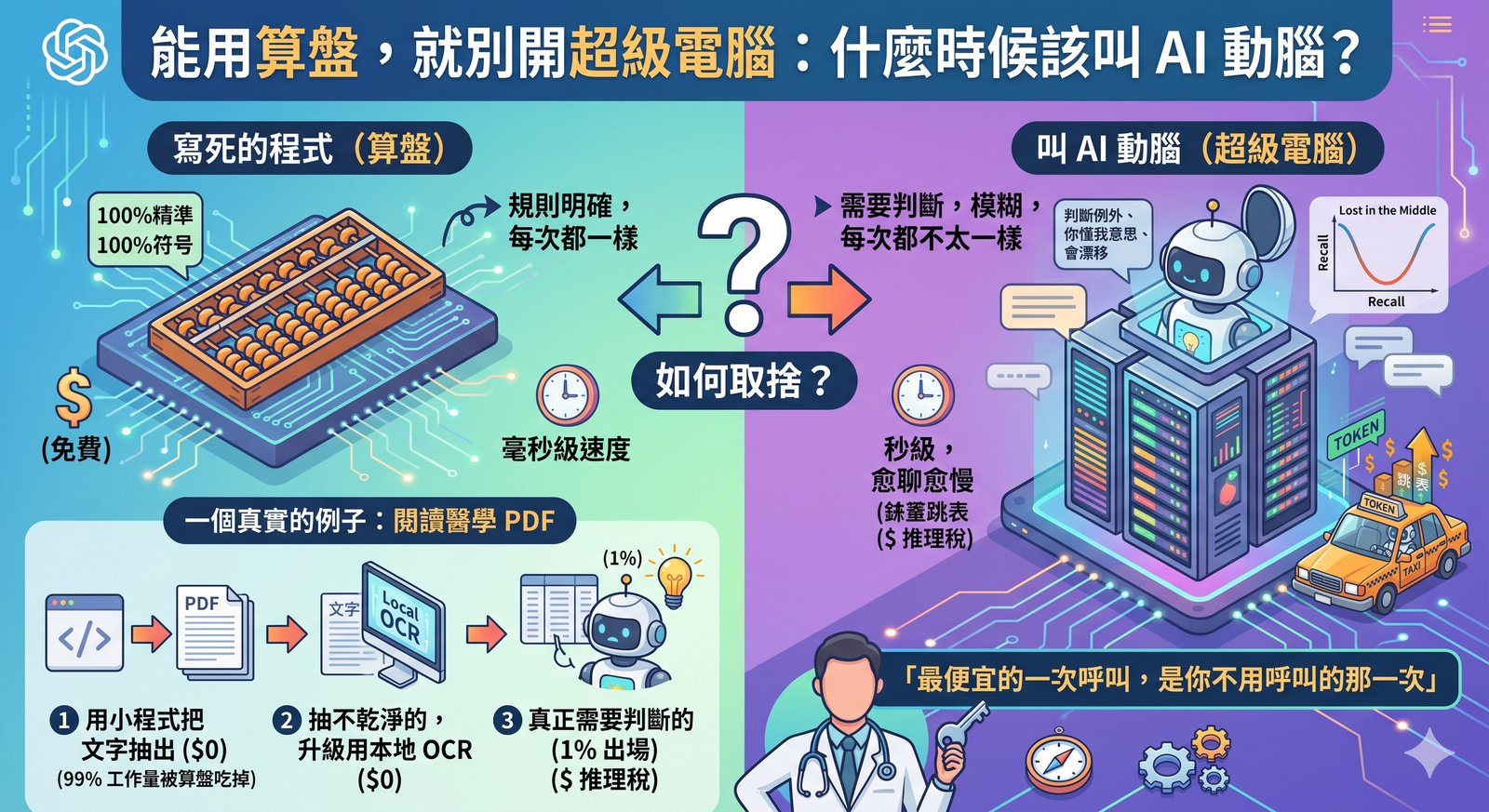
📖 省 Token 系列(共四篇):第一篇 為什麼你的 AI 越聊越笨 · 第二篇 能用算盤就別開超級電腦 · 第三篇(本篇)· 第四篇 我幫 AI 裝了一個省錢儀表板 前兩篇都還停在「人人可用」的層次。從這篇開始,我帶你看我電腦裡那套被我折騰到很細的設定。 先說背景。我除了在手機上用 AI 聊天,更常用的是一個叫 Claude Code 的工具:它跑在電腦的終端機裡,可以直接讀我的檔案、改我的筆記、幫我自動化一堆事。你可以把它想成「一個住在我電腦裡、能動手做事的 AI 助理」。 正因為它能做的事多、跑的次數多(一個任務動輒呼叫 AI 幾十上百次),省 token 在這裡的回報會被放大很多倍。而省 token 的第一原則,跟整理書桌一模一樣: 桌面上只放現在用得到的東西,其他都收進抽屜。 常駐稅:有一種成本,你每一句話都在付 我有一個檔案叫 CLAUDE.md,裡面寫著我給 AI 的長期規則:筆記要用什麼格式、哪些資料夾不要碰、我的偏好是什麼。 這個檔案有個特性:它在每次開工的最一開始就被載入,而且整段工作過程都常駐在 AI 眼前,不會被收走。 意思是,如果這個檔案有 5000 個 token,那麼無論我今天只問兩句、還是聊兩百句,每一句的背後都在重複付這 5000 個 token 的錢。 我把它叫做「常駐稅」。每一行都是稅。 所以我刻意把它壓在 95 行左右,只留真正穩定不變、非寫不可的規則。會議記錄、設計過程、長篇說明,全部移到別的地方,要用的時候才叫出來。 順帶一提,這些「只給 AI 看」的設定檔,我一律用英文寫。因為中文在 token 計算上比較貴(同樣意思的中文通常比英文吃更多 token),而給人看的筆記我才用中文。給 AI 的省錢,給人的好讀,各得其所。 抽屜:讓記憶分層,不要全攤在桌上 我給 AI 做了一套記憶系統,但重點不是「記越多越好」,而是分層: 真正天天用到的,放在最上層,每次開工自動載入。 偶爾才用的,收進抽屜,需要時才拉出來。 很久沒碰的,直接封存。 我還做了一個「使用熱度」的計分:常被讀到的記憶分數高、留在桌上;冷掉的自動往下沉。這樣桌面永遠只有當下最相關的那幾張紙。 道理跟上一篇的算盤一樣:這套熱度排序是用程式算的,不勞駕 AI。 這對手機聊天版的人也有啟發:ChatGPT 的「記憶」和「自訂指令」功能不是免費魔法,它是每次對話前自動幫你貼上去的隱形內容,一樣佔空間、一樣每句重算。所以記憶要精簡,不是塞越多越好。 ...