背景:我本來就在用的東西
念專科考試的時候,我給自己弄了一套 RAG(Retrieval Augmented Generation),用「看相似度」的語意搜尋(semantic search)把幾百本復健科教科書跟我自己的筆記變成可以查、可以問的東西。一邊在 Obsidian 裡讀書用,一邊讓 Claude 透過 MCP 也能找到我要的東西。
它目前最弱的地方,就是「跨文獻把知識串起來」。所以前幾天看到有人分享一篇剛發表的論文 SAG(SQL-Retrieval Augmented Generation),說可以在語意搜尋之外加上結構化查詢語言(SQL)跟圖的概念,讓跨文獻搜尋更容易,效果類似 GraphRAG 但更好維護、更好建立,我整個眼睛一亮。
在這時代想當然爾,就是把論文連結丟給 Claude,請他去讀論文、抓原作者的 GitHub、讀懂作法,然後用我自己的資料把整條管線複現出來、實際跑 benchmark XD
論文:Wu et al., SAG: SQL-Retrieval Augmented Generation with Query-Time Dynamic Hyperedges, arXiv:2606.15971。程式碼:github.com/Zleap-AI/SAG-Benchmark
第一步:選模型(RTX-3070 的眼淚)
整條管線裡最關鍵的一步,是用 LLM 把每段文字抽成「事件 + 實體」存進資料庫。原論文用 Qwen,我就比了本地的 Qwen(qwen3.5:4b)跟線上的 Claude Haiku。
結果 Haiku 萃取資訊的能力明顯比較好,實體圖更密、命名更一致(這對後面用 SQL 串很重要),而且看起來很便宜。這跟我先前的經驗相符,可能我的 RTX-3070 真的太弱了,稍微大一點的模型就跑不動(時代的眼淚阿),直接用 Haiku 又快又好!
順帶一提,我沒有 API 訂閱也能用 Haiku:直接派 Claude 的 subagent 去做,跑在既有額度內就好。
教科書上的三個發現(一路打臉)
我用神經復健的教科書當測試語料,設計了一批臨床問題,拿 SAG 跟原本的語意搜尋正面對決。結果分三關,每一關都打我臉一次。
第一關,單一本書:打平。語意搜尋已經夠強,多跳機制沒用武之地。
第二關,跨書、但問題裡把關鍵字都寫白了:還是打平。因為問題裡已經把「中風、脊張力、步態」全寫出來,語意搜尋自己就把相關段落都撈回來了。
第三關,跨書、但只問一端、中間那跳故意不講(例如只問「馬蹄內翻足怎麼處理」,期待它自己連到背後的脊張力機轉跟治療):SAG 終於贏了,而且贏很多。
| 隱性橋接題(只給一端) | 語意 baseline | SAG |
|---|---|---|
| 跨 3 本書 | 75% | 100% |
到這裡我超興奮,想說那書更多優勢應該更大吧?於是把語料加到 13 本。結果優勢不增反減:
| 隱性橋接題 | 語意 baseline | SAG | 差距 |
|---|---|---|---|
| 3 本書 | 75% | 100% | +25pp |
| 13 本書 | 79% | 83% | +4pp |
原因是,書一多就變冗餘,同一個概念在很多本書裡反覆出現,語意搜尋不靠那張圖也撞得到。SAG 真正吃香的場景,是「線索很少見、只藏在一兩個地方」的時候,跟我幾百本高度重複的教科書剛好相反。
所以對教科書庫來說,這是不需要增加的功能。
轉折:那「稀疏」的地方在哪?我的筆記庫
既然它在稀疏資料才吃香,我想到自己的 Obsidian 醫學筆記庫(約 2510 篇)。每個概念常常只出現在一兩篇,正好稀疏。
而且關鍵是:我的筆記本來就有用 wiki link 連著,那其實就是我人工建好的知識圖譜(GraphRAG 想自動生成的就是這種圖)。換句話說,SAG 要花 LLM 抽取才能得到的圖,我大半已經免費有了。
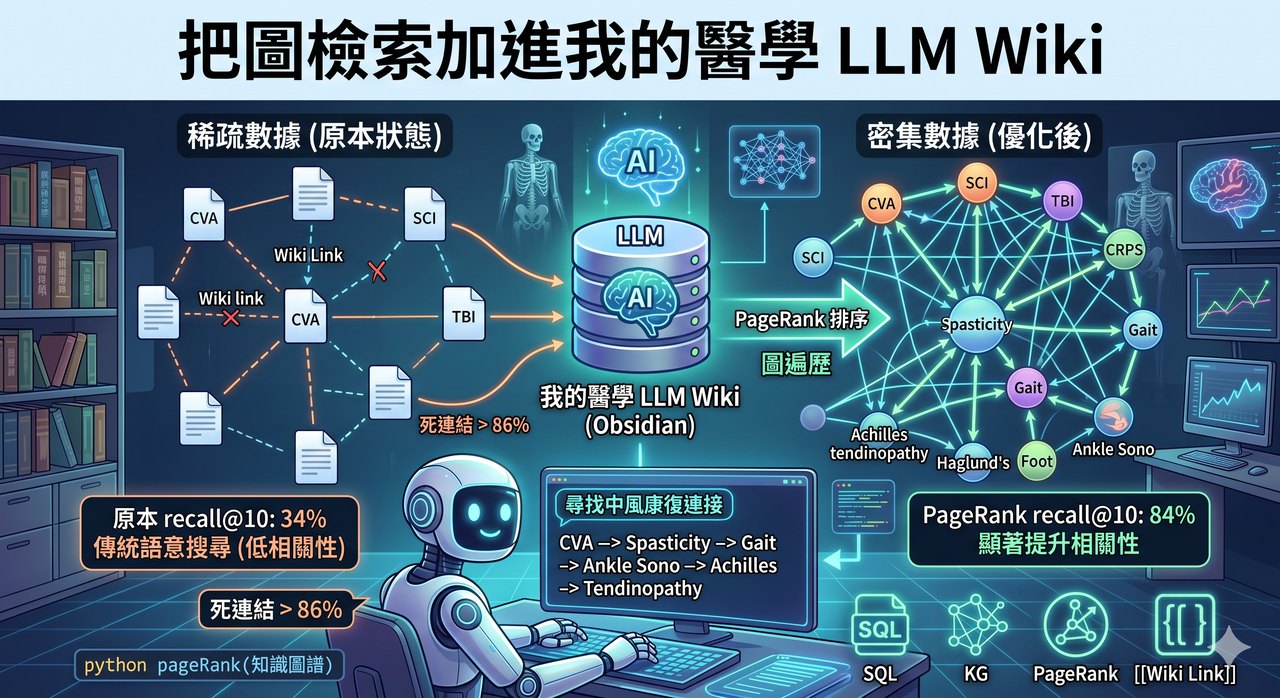
問題是從 Evernote 搬過來時掉了很多連結,圖很破。一量才發現我的「連結目標」裡有 86% 是死路(指向不存在的筆記、或只出現一次),真正能當「橋」的只有 700 多個。
先把連結補回來(純機械,不用審)
我請 Claude 寫了個小工具,掃過每篇筆記,只要內文字面提到另一篇筆記的標題,就在第一次出現的地方自動補上 [[連結]]。這是確定性的比對,不是語意判斷,基本不用我一條條審。
中間踩到一個雷值得記:一開始把「別名」也納入比對,結果縮寫大爆炸誤配,例如「WHO(世界衛生組織)」被連到別名為 WHO 的「腕手副木(Wrist-Hand Orthosis)」、英文字「was」被連到縮寫 WAS。後來收斂成「只連標題 + 安全的別名(多詞片語或中文譯名,例如 tennis elbow → 外上髁炎)」才乾淨。最後安全地補了幾千條連結。這批連結本身就是賺到,Obsidian 的 backlinks、graph view、導航全都一起變好。
找相關筆記:34% → 60%
接著測真正的用法:打開一篇筆記,自動找出相關的其他筆記。
| recall@10(找到正確的相關筆記) | 語意搜尋 | SAG(圖) |
|---|---|---|
| 找對的比例 | 34% | 60% |
幾乎翻倍。而且看實際例子就懂差在哪:
- 打開 [Sono - Ankle]:圖法連到 Haglund’s、旋後足、Achilles 肌腱病變、跗骨竇症候群(全是你掃腳踝會遇到的);語意搜尋則從腳踝不穩,漂到膝蓋、ACL、甚至髖臼。
- 打開 [CVA(中風)]:圖法連到脊髓損傷、橫貫性脊髓炎、創傷性腦傷、中風後 CRPS(整個神經復健的版圖);語意搜尋只在「中風」字面附近打轉。
圖法連到的是「概念上真的相關」的筆記,語意搜尋容易被字面相近帶偏。
請 Claude 研究生查文獻:60% → 84%
這時候就想,不可能只有這一篇新論文在搞「SQL/圖加進 RAG」,於是請 Claude 研究生繼續搜尋文獻。果然「語意 + 圖」的混合檢索是這一兩年的紅海:
- KG²RAG(NAACL 2025):語意給 seed chunks → 知識圖譜擴展。
- HopRAG(ACL 2025):語意相似起手 → 多跳鄰居探索 → 修剪。
- LinearRAG(2025):明講「用 LLM 抽關係建圖又貴又不穩」,主張用輕量、relation-free 的圖。剛好替我們的做法背書。
- MiniRAG(2025):給小模型用的輕量圖 RAG,省 75% 儲存。
- LightRAG(EMNLP 2024):dual-level(local/global)混合檢索。
我們的東西不新奇。但這是好消息,代表方向對、可以直接站在別人肩膀上。
比對之後,最值得抄的是 排序方法。我一開始的排序很 naive,就是「數共享幾個連結」;換成 LinearRAG/HippoRAG 那派的 personalized PageRank(從種子筆記出發,沿著連結做「帶重啟的隨機漫步」,讓分數沿圖擴散聚合),結果再跳一大階:
| 排序方法(同一個 wiki link 圖) | recall@10 |
|---|---|
| 語意 baseline | 34% |
| 共享連結計數(naive) | 60% |
| personalized PageRank | 84% |
不同 K 也一致(@5:23% → 46%;@10:34% → 60% → 84%;@20:45% → 72%)。而且它完全不用 LLM、是即時的(純 numpy)。換句話說,圖的來源(現成 wiki link)跟排序法(PageRank)這兩件事,後者才是真正拉開差距的關鍵。
我也把 LightRAG(現成的 Graph RAG 引擎)抓來比:用它的 insert_custom_kg API 把我的 wiki link 圖塞進去是行得通的(不用它自己的 LLM 抽取),但它每次查詢都要先用 LLM 抽關鍵字,大概 20 秒一次,慢很多,而且對「找相關」沒有比較好。所以 LightRAG 留給「自由問答」用,「找相關筆記」就用我們這套輕量的。
然後我直接把它接上線了
最後我請 Claude 把這套 PageRank 排序,接進我自己在用的 vault search 系統(一個本地的 MCP server + Obsidian 外掛):
- 新增一個純 PageRank 的「找相關」工具。
- 把原本「找相關筆記」用的純語意排序,換成「語意 + PageRank」的融合(用 reciprocal rank fusion 把兩個排名合起來)。
因為我外掛的「相關筆記」面板本來就打那支 API,所以連外掛都不用改,整個就一起變好了 😄
結論
- 教科書庫(大、冗餘):不必加,語意搜尋已經夠好。
- 筆記庫(小、稀疏、已有人工連結):很適合,完全跑在我既有的 wiki link 上,免 LLM 抽取、零維護漂移。已經上線。
- 關鍵變數有兩個:一是「怎麼問」(靠筆記連結去串相關筆記,比自由文字搜尋強);二是「怎麼排序」(PageRank 式擴散 > 單純數連結)。
- 而且這趟順手把破掉的筆記連結也補回來了。
能這樣把一篇論文整個丟給 LLM,請他自己去讀、去學、去測、最後還幫我接進系統,真的又方便又有趣。逛臉書逛一逛,順手就把一個新方法在自己系統上驗證完、還上線了 😆
下一篇,我會把這整套 vault search 怎麼做的攤出來講:Obsidian 外掛 + 本地 MCP server、語意 + 圖、怎麼建索引怎麼查,那才是我每天真正在用的。
參考文獻
- SAG:Wu et al., SAG: SQL-Retrieval Augmented Generation with Query-Time Dynamic Hyperedges, arXiv:2606.15971(github.com/Zleap-AI/SAG-Benchmark)
- KG²RAG:Zhu et al., Knowledge Graph-Guided Retrieval Augmented Generation, NAACL 2025
- HopRAG:Liu et al., HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation, ACL 2025
- LinearRAG:Zhuang et al., LinearRAG: Linear Graph Retrieval Augmented Generation on Large-scale Corpora, 2025(github.com/DEEP-PolyU/LinearRAG)
- MiniRAG:Fan et al., MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation, 2025(github.com/HKUDS/MiniRAG)
- LightRAG:Guo et al., LightRAG: Simple and Fast Retrieval-Augmented Generation, EMNLP 2024(github.com/HKUDS/LightRAG)
- HippoRAG:Gutiérrez et al., HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models, NeurIPS 2024