📖 省 Token 系列(共四篇):第一篇(本篇)· 第二篇 能用算盤就別開超級電腦 · 第三篇 幫 AI 整理一張乾淨的工作桌 · 第四篇 我幫 AI 裝了一個省錢儀表板
你一定有過這種經驗:跟 ChatGPT 或 Claude 聊一個下午,越到後面它越遲鈍,回得越慢,還會突然「忘記」你前面講過的事,甚至開始鬼打牆。
很多人以為是自己網路慢,或是 AI 當機。其實不是。這背後有一個大多數人不知道、但知道之後會立刻改變你用法的真相。
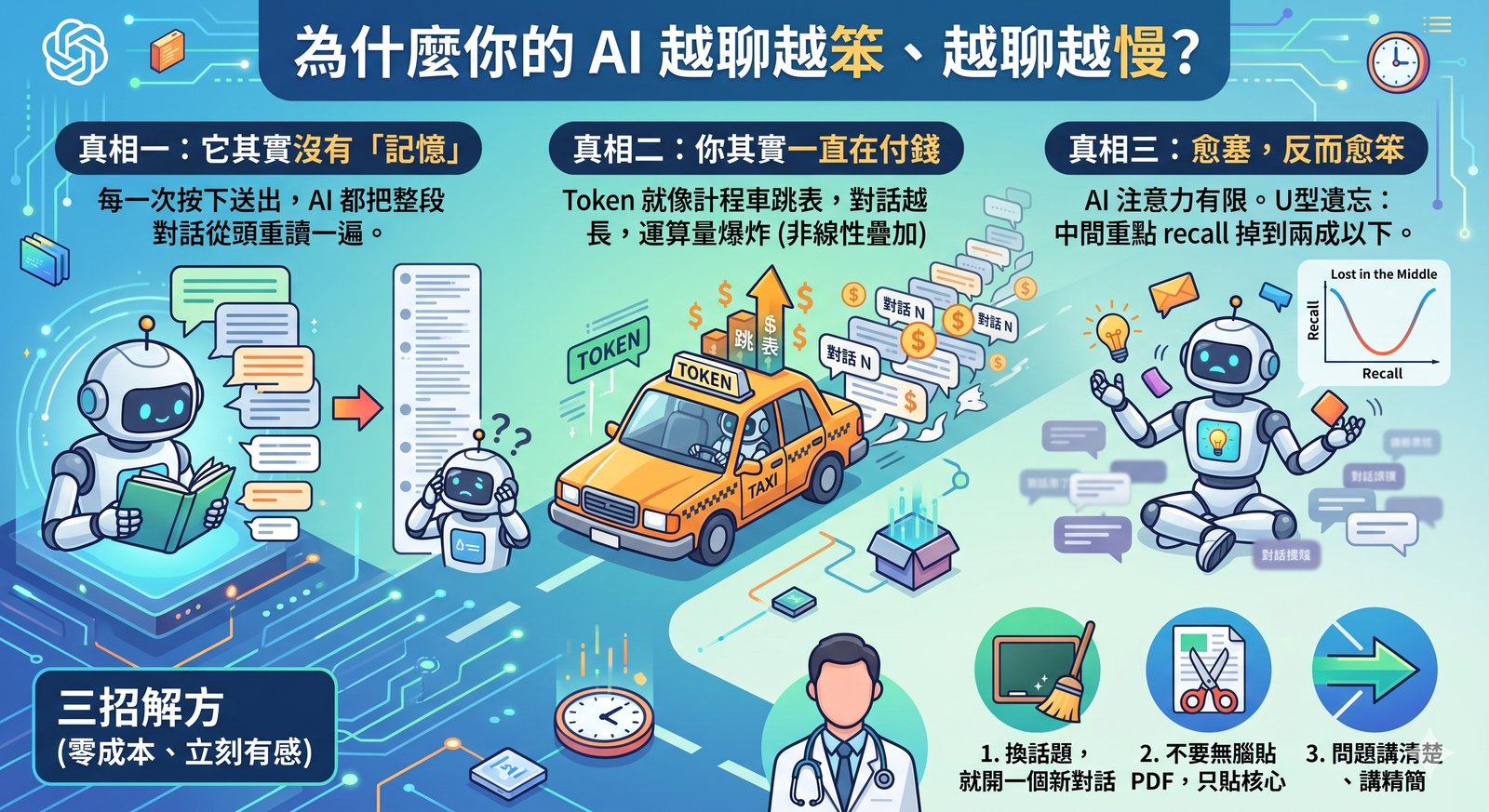
真相一:AI 其實沒有「記憶」
我們直覺以為,AI 像人一樣,聊著聊著就「記住」了對話。
它沒有。
每一次你按下送出,AI 都把你們從第一句到現在的整段對話,從頭重讀一遍,然後才回你下一句。它不是接著上一句講,而是每次都把整本對話重新看過。
所以你可以想像:對話越長,它每回答一句之前要重讀的東西就越多。這就是為什麼越聊越慢。
真相二:你其實一直在付錢,只是看不到帳單
AI 處理文字的單位叫 token(大致是一個字或半個詞)。你輸入的每個 token、它輸出的每個 token,背後都在計費。
最好記的比喻是:token 就是 AI 的計程車跳表。 距離(字數)越長,車資越高。
你在訂閱制的 App 裡看不到這張帳單,但它換了一張臉出現在你面前:就是那個「你今天的訊息額度已用完」,還有「怎麼越來越慢」。額度和卡頓的背後,都是 token 的運算量。
而且這筆帳不是線性疊加的。對話長度加倍,你付的運算量不是兩倍,而是接近四倍(這是 AI 內部運算機制的數學特性)。難怪長對話的卡頓感像在爆炸。
真相三:越塞,反而越笨
這點最反直覺,但最有用。
AI 的「注意力」是有限的,所有注意力加起來永遠等於一份。你塞進去的內容越多,每個重點分到的注意力就被稀釋得越薄。多餘的廢話會偷走本該分給關鍵問題的專注力。
這不是我隨口說的。一篇很有名的研究 Lost in the Middle(Liu et al., 2024)發現一個 U 型曲線:資訊放在對話的開頭或結尾,AI 記得最牢;但埋在中間的重點,記得的機率會掉到只剩大約兩成。難怪它常常把你中間講的事忘光光。
另一份 Chroma 在 2025 年的研究測了 18 個主流模型,發現它們全部都隨著輸入變長而表現下滑,這現象被叫做 context rot(脈絡腐化)。
所以結論很簡單:少即是多。 給 AI 剛剛好的資訊,它不只更便宜更快,還答得更準。
那我今天能做什麼?三招,零成本,立刻有感
第一招:換話題,就開一個新對話
這是最有效、最容易忽略的一招。你跟它聊完旅遊行程,接著要它幫你改履歷,別在同一個對話裡接下去。開個新的。
舊對話對新主題不但沒幫助,還會把上一個話題的語氣和假設硬帶進來干擾。開新對話就像把寫滿舊算式的白板擦乾淨再寫,AI 反而更聰明。
很多人會擔心:開新對話,舊的資料會不見嗎?不會。舊對話還乖乖躺在你的側邊欄,你隨時找得到。開新對話只是讓「這個新對話裡的 AI」看不到舊的那些,不是把它刪掉。
第二招:不要整份 PDF、整篇長文無腦貼進去
你貼進去的每個字都算錢,而且接下來每一輪對話都會被重複計算一次。貼一份你其實只用得到一段的長 PDF,等於往後每句話都拖著整份文件的重量在走。
只貼你真正要問的那一段就好。
第三招:問題講清楚、講精簡
這不只省錢,還讓回答更準(還記得真相三嗎?)。與其給它一大段背景再含糊地問「你覺得呢」,不如直接說清楚你要什麼。
為什麼我會在意這些?
我是一個復健科醫師,平常把 AI 用得很兇:整理筆記、查文獻、自動化一堆生活雜事。用得越深,我越發現「省 token」這件事,根本就是在訓練自己「把話講清楚、把工作整理乾淨」。
有趣的是,我後來把 AI 從手機聊天 App 一路用到電腦上更進階的工具,發現我在進階工具裡做的每一個省錢動作,本質上都跟上面這三招一模一樣,只是換了名字。
那是一條從手機到終端機都通用的同一條原理。下一篇,我會講一個關鍵的分水嶺:什麼時候該叫 AI 動腦,什麼時候根本不該用 AI?
—
➡️ 下一篇:能用算盤,就別開超級電腦:什麼時候該叫 AI 動腦?
參考資料
- Liu, N. F., et al. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12:157–173. arXiv:2307.03172
- Chroma Research (2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance.